In this blog post, we try to answer the question: “Why does Code Compass focus on library-level code reuse?” The tl;dr answer: because libraries are many, they are varied, they die young and they’re well-organized. Read on to learn more.
If you try out Code Compass you will notice that it lets you explore open source software at the level of individual software libraries, also called ‘modules’ or ‘packages’. We source these results from libraries that are catalogued in so-called “package repositories”: large repositories of reusable software components, specific to a certain programming language, such as the Python Package Index for Python.
There are certainly other levels at which one could explore open source software, such as at the level of large projects or frameworks (this is more or less what BlackDuck’s Open Hub allows you to do) or at the level of very fine-grained code snippets (like browsing GitHub gists or StackOverflow) So why did we choose to go with library-level recommendations?
One reason is that we wanted Code Compass to be a tool that boosts code reuse. Libraries published in package repositories are designed for code reuse. There’s no point in publishing a software package to a repository if you don’t want it to get reused by others.
Another reason is that libraries strike a ‘sweet spot’ between the amount of time a developer spends looking for particular functionality versus the payoff in terms of the number of lines of code that can be reused. This is illustrated in the figure below.
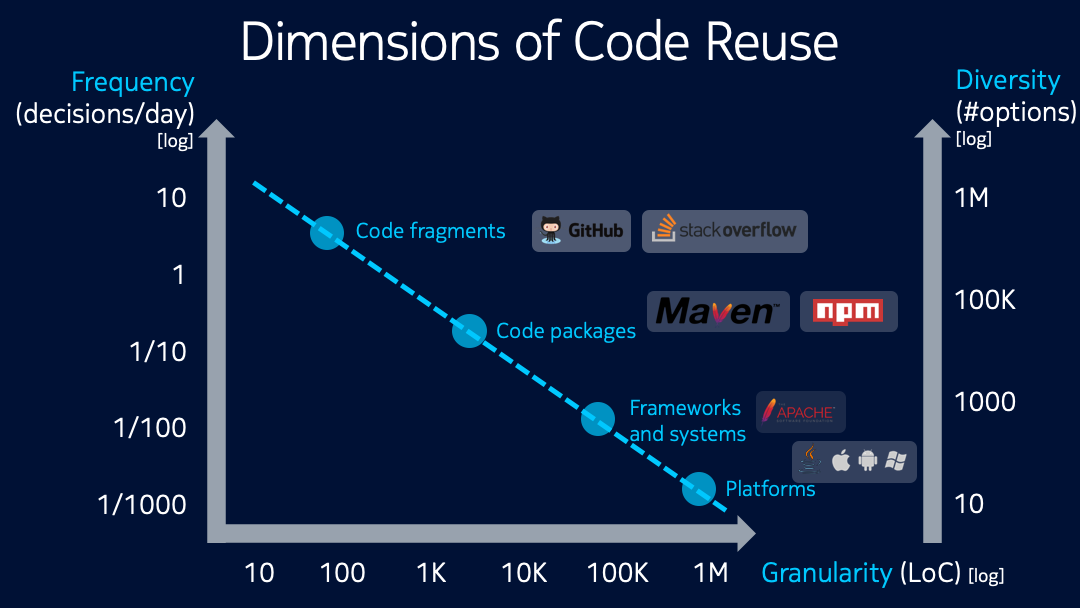
The figure shows how different kinds of software components (approximately) relate to each other according to three dimensions. Let’s first go over the dimensions one by one:
-
Frequency indicates how often a developer is confronted with the task of finding a certain type of component to reuse. For instance, how many times per day/week/month does a developer spend time searching for a new or alternative component of this type?
-
Granularity is a measure of the size of the component (e.g. number of lines of code) and correlates with the amount of work a developer saves by reusing the component rather than writing it herself.
-
Diversity simply indicates the number of components of this type a developer can typically choose from, i.e. the amount of choice.
All axes are on a log10-scale (multiples of 10x), and are meant to indicate a general order of magnitude, rather than to be a precise measurement. The trend line is meant to indicate a reciprocal trade-off between frequency and granularity: the larger the component to be reused, the less frequently you’re going to need to find new or different ones.
Platforms: too few, too large and too stable
Let’s start in the bottom right corner: platforms are extremely large components such as the JDK, the iOS and Android platforms, Chromium/WebKit, or Windows. By building your software solution on top of a platform, as a developer you save (reuse) millions to tens of millions of lines of code, and years of development effort. Despite this, it doesn’t really make sense to build a tool like Code Compass for such platforms, because the choice among platforms is really limited, and because the frequency of code reuse is so small (you don’t need to evaluate them often, because they don’t come and go that fast). In the course of your entire career as a software developer, you might switch among such platforms maybe 5-10 times, and even then, your decision to choose for a platform will likely not be determined by your own preference, but by the market.
Frameworks and systems: too widely known and still too stable
Moving left and up, we arrive at software components such as large frameworks and systems like most of the top-level Apache projects (Apache Hadoop, Apache Spark), DBMSes (e.g. MariaDB) or Message Busses (e.g. RabbitMQ). Much like platforms, reusing such components introduces a big payoff for a development team, enabling hundreds of thousands (often even millions) of lines of code to be reused. But much like entire platforms, you will likely be using these frameworks for many years, and the decision to choose one framework over another is often not made by individual developers. In addition, the number of frameworks to choose from is sufficiently limited that most developers will have heard of the most important frameworks through peers, conferences and online articles. This again dilutes the value of having a search engine. However, successful frameworks and systems often grow a rich ecosystem of tools, utilities and plug-ins around them, and these often get published as smaller, independent code packages.
Code fragments: too disordered
Jumping to the top left corner, we find code fragments. Now things start to become interesting: in terms of diversity, there are millions upon millions of lines of code that developers can now find on the Web, be it as part of code repositories such as GitHub (which by end of 2018 hosted over 95 million code repositories) or as part of technical Q&A websites such as StackOverflow (which hosts millions programming-related question-answer threads, many of whom contain code snippets). In terms of frequency, a developer working on a piece of code may issue multiple search queries per day, or even per hour, when working with code with an unfamiliar API. So it seems code snippets definitely could benefit from a dedicated search engine, and indeed some of these engines exist.
A key difficulty with code snippets, however, is that they are not a good unit of reuse: they come with little documentation about their API and their dependencies on other code are usually left implicit. While some code snippets are generic and reusable (such as math formulae, sorting algorithms, or boilerplate code to e.g. open a database connection) the majority of code snippets are rather too tied to the specifics of a single project. That makes for two problems: 1) the lack of documentation or structured meta-data makes finding the relevant code difficult and 2) search results often need extensive “editing and repair” before they can be used effectively. There are other problems as well, such as the lack of copyright or licensing information, making inclusion into a corporate codebase problematic.
Code packages: many, varied, high churn
And so we arrive at the final software component: code packages (aka modules or libraries). Code packages, unlike code snippets, are designed to be reusable components: they come with API documentation (the good ones, at least), and with explicit dependencies. A code package is designed to be linked into your codebase, usually at build-time or run-time. Because of this, code packages often assume a common programming language and associated toolchain, which is why we see in practice that code packages are published on distinct package repositories, often one per programming language. Three of the largest ones include Maven Central for Java, NPM for JavaScript and PyPI for Python.
Code packages can vary tremendously in size and functionality (in fact, we have detailed statistics about this in our MSR paper), from tiny packages that expose just a single function (e.g. to compute the distance between two (latitude,longitude) coordinates using the Haversine formula), all the way up to toolkits such as Python scikit-learn (a comprehensive machine learning toolkit), but often will let you reuse on the order of hundreds to tens of thousands of lines of code. This is still a big payoff in terms of saved development effort. On the other hand, developers need them often: writing any significant software product often entails thousands of little tasks, from rendering a UI component in a specific way, to parsing a specific file format, to implementing a specific network protocol, to complex math, machine learning, data analysis, etc. etc. The list is nearly endless. Each of the tasks is fairly small and specialist, but the development effort to address each of them adds up quickly.
That’s why I believe a search engine for code packages like Code Compass hits a sweet spot: it balances frequency (multiple searches per week) with granularity (thousands of lines of code reused) with diversity (hundreds of thousands of packages to choose from). At the same time, code packages are specialist enough that developers themselves are often empowered to choose the one that best fits their context, and there is often an explicit license so that the legal ramifications of reusing a particular package are clear from the get-go.
Wrapping up
So there you go, that’s the long answer to why Code Compass is not a source code search engine like GitHub code search, nor an open source search engine like OpenHub. Code packages hit the sweet spot in terms of frequency, granularity and diversity, and that’s why they deserve a tool like Code Compass, which can pick out the best possible code packages for a developer’s development context and needs.