One of the key tenets of software engineering is to build larger software from smaller pieces, where the smaller pieces can be developed independently and packaged as libraries for reuse in many projects. While this practice has existed since the dawn of software engineering, the rise of the internet, the Web and Open Source brought about an exponential growth in the total number of available library packages or modules for all of today’s most widely used programming languages. With package managers such as NPM growing to over 800K packages and becoming the largest software repository in the world the trend clearly points in the direction of ever smaller and more specific libraries that get mixed-and-matched to suit the needs of a developer’s specific software project.
At Nokia, as in most large technology companies, our products are now built from tens of thousands of open source software packages large and small. While such large open source software ecosystems are generally a boon to developer productivity, we are reaching a tipping point where the deluge of new libraries that become available every single day introduces entirely new kinds of problems. One such problem is that finding the most relevant library for a given task in a specific developer context is growing more challenging. One way in which developers deal with this discoverability problem is by publishing and sharing curated lists of libraries, as witnessed by the popular “awesome lists” on GitHub.
While these lists certainly are valuable due to their curation by a large developer community, they hardly form a scalable way of indexing today’s open source ecosystems. As one data point, the website LibHunt which is based on such lists has indexed on the order of 24,000 projects whereas according to the website ModuleCounts the total count of the top 6 most popular package repositories well exceeds over 1 million packages and so most packages in the “long tail” remain undiscoverable through manual curation.
The size and scale of today’s software ecosystems suggests that a machine learning approach could help us build tools that help developers more effectively navigate them. However, for most learning algorithms to be applied successfully to this problem, we require a mathematical representation of libraries, preferably one that represents similar libraries by similar mathematical objects.
Measuring similarity between libraries
If we were able to cluster libraries by their semantic similarity, we would be able to more effectively categorize a larger fraction of the growing library ecosystems, in turn helping developers find more relevant libraries. But how can “semantic similarity” be defined for libraries? There are many valid interpretations: the libraries could offer the same functionality, could both be extensions of the same base framework, could follow the same API guidelines, could be written by the same author, and so on.
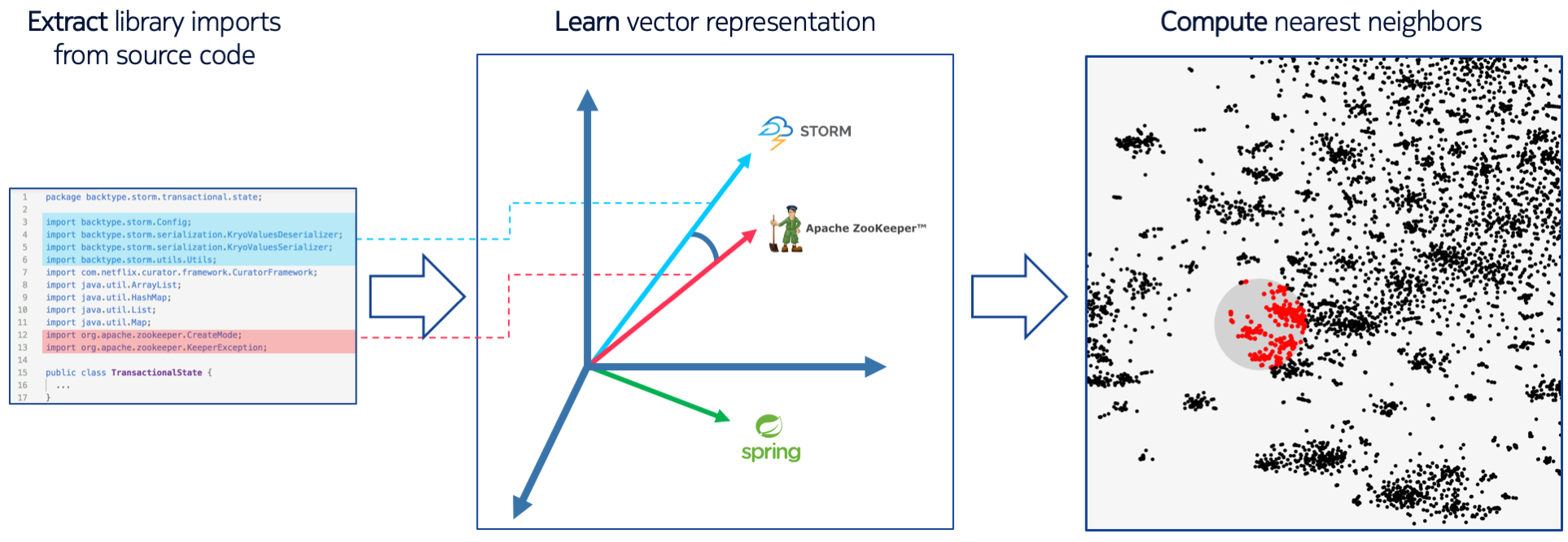
One way to measure “semantic similarity” of libraries is to consider their “context of use”: the set of other libraries that are also frequently used by code that imports the target library. By this measure of similarity, Python libraries such as NumPy and SciPy would be very close, as SciPy (a toolkit for scientific programming) builds on the data types provided by NumPy (N-dimensional arrays).
To identify the co-occurrence of libraries in source code one can look specifically at import statements, which are often used in very idiomatic ways across projects and languages. Consider the following Python script:
import numpy as np
from scipy import linalg
A = np.array([[1,2], [3,4]])
linalg.inv(A) # invert matrix A
The import statements reveal that libraries “numpy” and “scipy” co-occur in this source file. If this combination appears in many source files across many different projects, it is reasonable to infer that the libraries are closely related. We will see later how this simple observation forms the key idea behind developing a similarity measure for libraries. Once we have such a measure of similarity, we can use it to build tools that help developers more effectively navigate large open source ecosystems. But first, let’s turn our attention to why having a measure of similarity between libraries is needed.
Machine learning representations
Machine learning typically requires the input data to be in some numerical form. For instance, it is common to represent images as matrices of numbers (representing the color intensities of each pixel), sound as a vector of sampled amplitudes and words in a text as indices in a vocabulary.
Libraries are typically identified by a unique name, and in that sense they are just unique words or labels. A common technique in machine learning to mathematically represent such labels is to encode them as sparse vectors: each vector has a number of entries equal to the total number of possible labels (in our case: equal to the total number of distinct libraries in our dataset) with one entry set to 1 and all other entries set to 0. Each different library will have a ‘1’ in a different position. This is called a ‘sparse’ or ‘one-hot’ encoding because the vast majority of entries in the vector is set to zero. The figure below illustrates the idea:
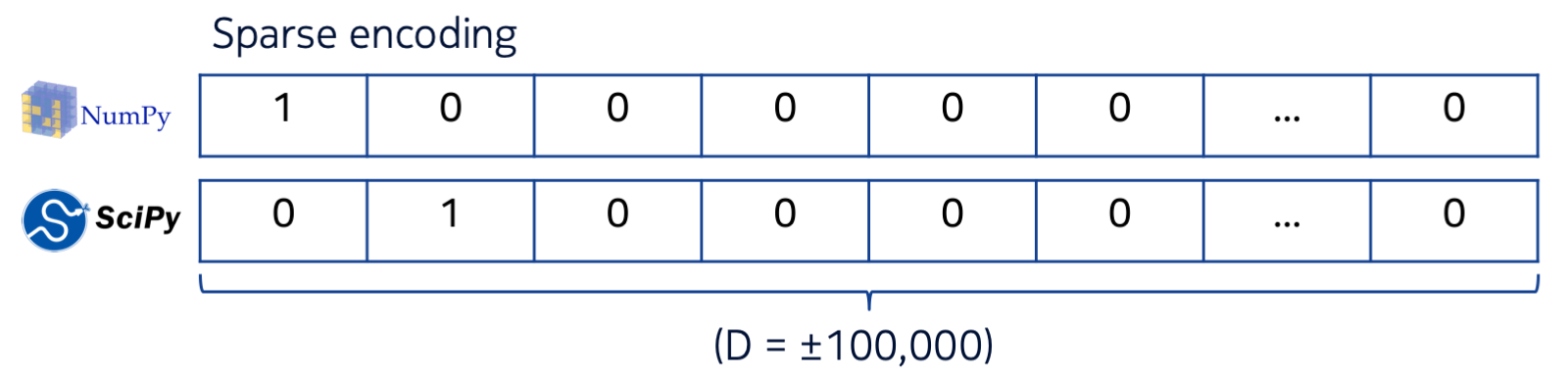
There are a few problems with this representation. First, if we have many possible labels, the representation becomes unwieldy. For example, there are over 800K libraries hosted on NPM. Representing each as a sparse vector of 800K components is cumbersome (requiring dedicated sparse matrix libraries and careful thinking in order not to hit memory limits). Second, each of these sparse vectors is fully orthogonal to all the other vectors, meaning that all the libraries are equally distant from each other. That means our sparse representation cannot be used as a similarity measure: closely related libraries like NumPy and SciPy are equally distant compared to any two unrelated libraries.
This isn’t a new problem: researchers in the field of natural language processing (NLP) that need to apply machine learning on text often encounter similar problems when considering the representation of words in text, and need ways of representing words as shorter, more dense vectors such that closely related words get similar vector representations. Such a dense vector representation is also called an embedding. The figure below illustrates the idea:
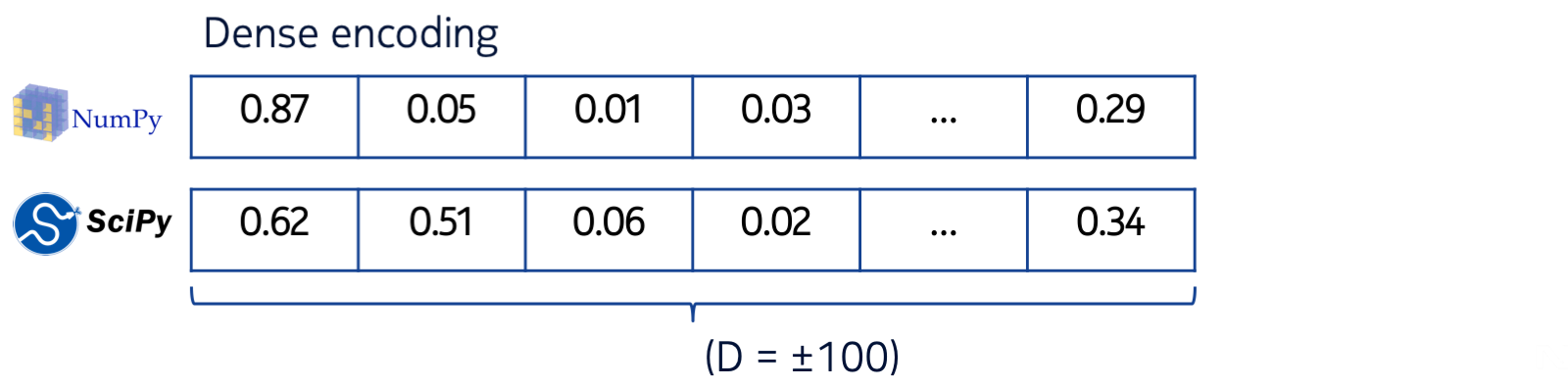
Compared to a sparse encoding, a dense encoding typically has a far smaller number of dimensions (on the order of 100 or 200), and each entry in the vector is now no longer just a binary 0 or 1, but a scalar value. However, compared to the sparse encoding, the “meaning” of each dimension is no longer obvious: it is learned by a machine learning model from data, rather than assigned by a human. To determine the similarity of two dense vector embeddings, one can compute their cosine distance, which returns a single number quantifying how well the vectors are aligned.
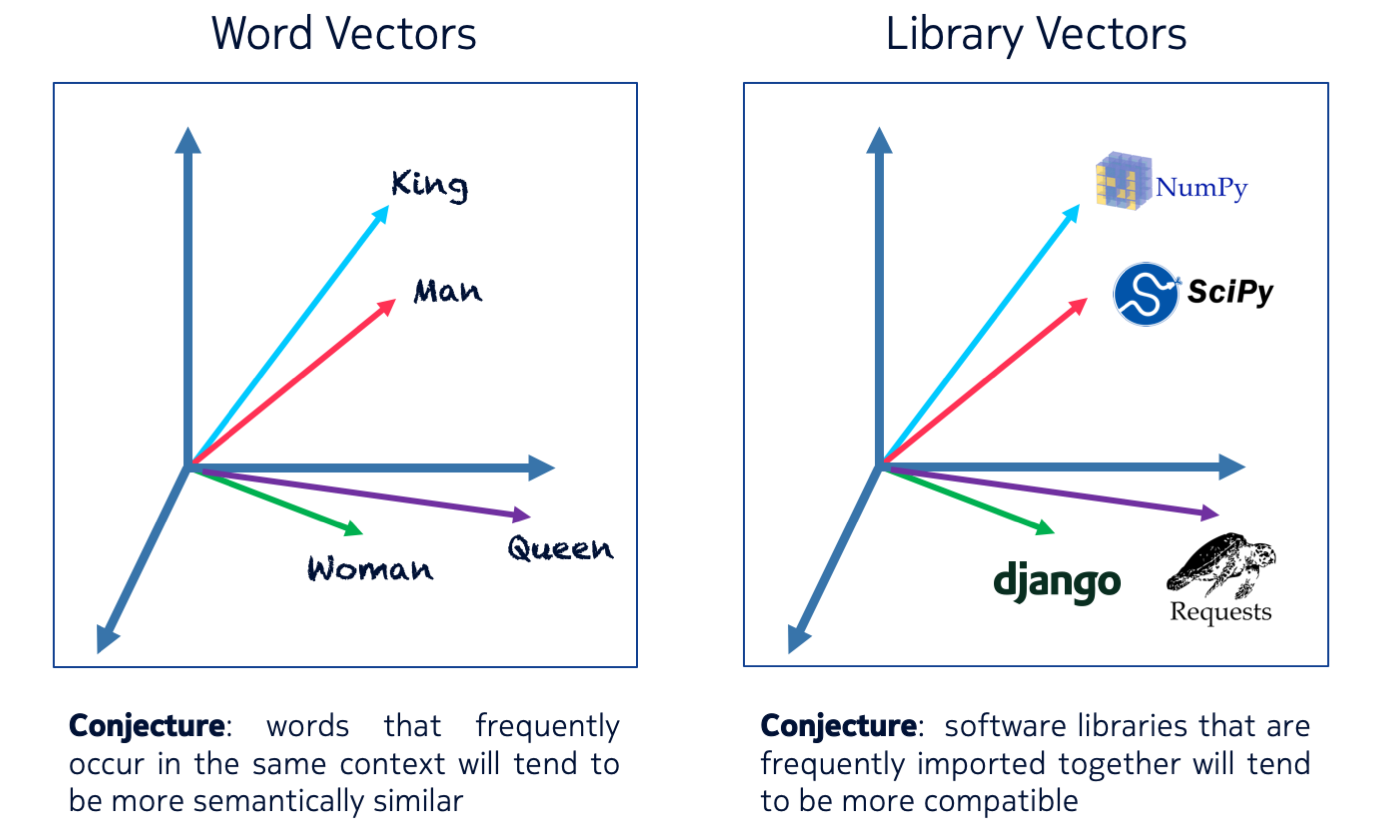
Word embeddings received widespread attention after Google researcher Tomas Mikolov and colleagues released word2vec, a practical method to train such dense embeddings efficiently on very large text corpora. Could we leverage these techniques to represent libraries? The answer is yes: just like word embeddings learn to represent similar words by similar dense vector representations based on the words’ similar context of use, we can learn a dense vector representation of libraries based on their context of use. By analogy with the term “word vectors”, we call our embeddings “library vectors”. The figure below illustrates the key idea:
Our learning technique, which we dub import2vec - by analogy with word2vec - can learn such domain knowledge without any “supervision” (i.e. without any explicit examples of similar libraries). Instead it learns them in an “unsupervised” way, by reading lots of source code and taking note of co-occurrences among libraries in source files, as illustrated previously for NumPy and SciPy in the example Python script. The full details of the training procedure can be found in our MSR 2019 paper.
Just like word vectors are trained on large corpora of natural language text, library vectors require large corpora of source code. For word vectors, we know that training them on a large corpus of text leads to words that appear often in similar contexts, such as ‘king’ and ‘queen’, end up in similar parts of the vector space. There is also evidence that suggests that the vectors encode relationships among words, such that vector(‘capital’) + vector(‘Germany’) is close to vector(‘Berlin’), and vector(‘king’) - vector(‘man’) + vector(‘woman’) is close to vector(‘queen’). So we were curious to discover what would happen when we train library vectors on a significant fraction of open source code. That’s what we’ll dive into next.
Exploring software ecosystems
We trained library vectors for today’s three most popular programming languages: JavaScript, Python and Java (based on the total number of contributors on GitHub). As the input to train our embeddings, we used the source code of libraries published in the main package repository of the language (NPM for JavaScript, PyPI for Python and Maven Central for Java) in combination with a large set of projects available on GitHub. To get a sense of the scale of the corpus, for Java, we processed about 29 million source files containing 238 million import statements, importing 10.6 million unique Java package names. The full details of our corpus can be found in our paper.
There’s a snatch however: how do we know whether the embeddings learned by our model are any good? There is no labeled data set that will tell us, for a given pair of libraries, how ‘related’ they are. One thing we can do is visualise the embeddings and explore them, to see whether the data is clustered according to semantically relevant topics (this requires human judgment - in this case, the judgement of a software developer familiar with a given language’s ecosystem).
But how do we visualise a 100-dimensional vector space? Unfortunately we can’t - directly - but there exist data science techniques that can help us. Through a process called “dimensionality reduction”, data scientists routinely visualise high-dimensional data in just two or three dimensions. The particular technique that we used for our experiments is called t-Distributed Stochastic Neighbour Embedding or t-SNE for short. Without going into too much technical detail, t-SNE reduces the number of dimensions in a dataset in such a way that data points that form clusters in lower dimensions are likely to also be clustered in the original high-dimensional space. As with all dimensionality reduction techniques, there are many pitfalls and there is always the risk of seeing patterns that aren’t really there. But when used with caution, techniques like t-SNE are extremely powerful and can scale to large datasets.
So back to visualising our trained library vectors. Below are 2D t-SNE plots for each of the three software ecosystems we studied. Each black dot is a library package registered in the language’s main package repository. Libraries are clustered, and we annotate some of the identified clusters with the names of dominant libraries in the cluster, or with the common functionality associated with libraries in the cluster. Click the figure to see a high-res version.

Notice the red square in the top right corner of the Python ecosystem. Below is a blow-up of that region, which highlights the nearest neighbours to the NumPy library mentioned earlier:

Python data scientists will no doubt recognise other commonly used data science and machine learning libraries including scipy, matplotlib, pandas, sklearn and keras.
Below is another example, this time from the JavaScript (NPM) ecosystem. The figure below shows the region around the bitcoinjs-lib library, revealing several related cryptocurrency projects (e.g. ethereumjs-tx) and more general-purpose cryptography libraries (such as crypto-js and aes-js).

We can also use t-SNE to project down to 3D rather than 2D, revealing more structure. Below is a plot of a subset of the Java ecosystem, highlighting the locations of several Apache open source projects:

Note how “big data” Apache projects like Kafka, Zookeeper, Mahout and Spark all cluster together in the green area of the ecosystem.
What about the analogies using vector arithmetic such as the ‘King’ - ‘Man’ + ‘Woman’ = ‘Queen’ example? In general these kinds of analogies are harder to construct for libraries, but we did find some evidence that the vectors encode relationships between libraries, such as that between frameworks and their utility libraries. For instance, the popular JavaScript-based web framework express has a small utility library called body-parser which adds the ability to parse the body of incoming HTTP requests. An alternative web framework called koa has a similar utility called koa-bodyparser. We found that vector(‘koa-bodyparser’) is the second nearest vector to vector(‘body-parser’) - vector(‘express’) + vector(‘koa’). In a similar vein, we found that our library vectors directly encode the relationship that react-bootstrap is to react as angular-ui-bootstrap is to angular. A few more examples are explored in the paper.
From all of the examples above, it seems that local regions in the library vector space encode rich domain knowledge related to software development. The next question we turn to is how we can make this domain knowledge accessible and useful to software developers at large.
Putting library vectors to work: contextual search
When developers work on a software project, they rarely start developing code from scratch. Instead they build on libraries they are already familiar with or they join a project that already has a rich technology stack in place.
Library vectors allow us to interpret the known library dependencies of a project as vectors, which in turn allow us to “position” a software project in the larger developer ecosystem. When developers search for libraries, we can exploit the knowledge of the local ecosystem encoded in the vectors to generate search results that are tailored to the developer’s specific context, by listing search results ranked according to distance in library vector space. Thus, library vectors enable a contextual search engine for library packages. The figure below illustrates the key idea:
We took this idea and made it real. We call the resulting search engine Code Compass, as it is a tool that helps developers more effectively navigate open source ecosystems. Below is a screenshot of the tool in action:
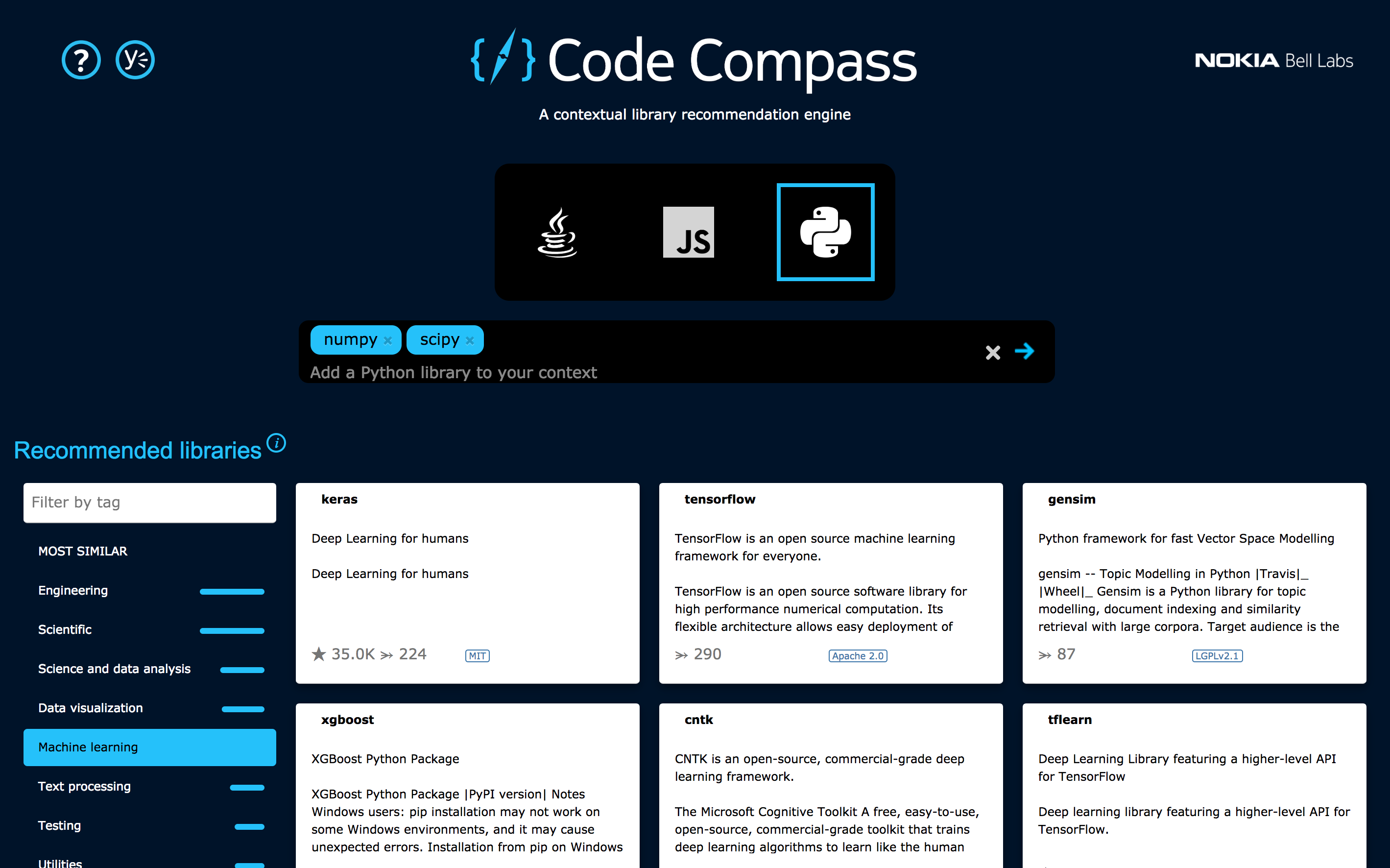
The developer entered the Python NumPy and SciPy libraries as search context, and Code Compass returned the most relevant libraries for the developer to explore. Search results can be filtered by tags, license terms, etc. In this case, the developer filtered the search results to only show libraries tagged with the term “machine learning”.
It’s also possible to seed the search context with “negative” examples of libraries, by prefixing their name with a minus sign, in which case Code Compass will use vector subtraction rather than vector addition to compute the search context. This enables a kind of “search by analogy”. The screenshot below illustrates this with the JavaScript example described previously (libraries used as negative anchors are marked red in the search context):

It’s also possible to seed the search by dragging a source file or a project manifest (e.g. an NPM package.json file, a PyPI requirements.txt file or Maven pom.xml file) into the search box to have Code Compass automatically extract library dependencies from code.
We took this a step further and developed IDE extensions that allow developers to summon Code Compass directly from within their IDE, with the search context automatically seeded by the code they are currently working on. Below is a screenshot of our visual studio code extension:
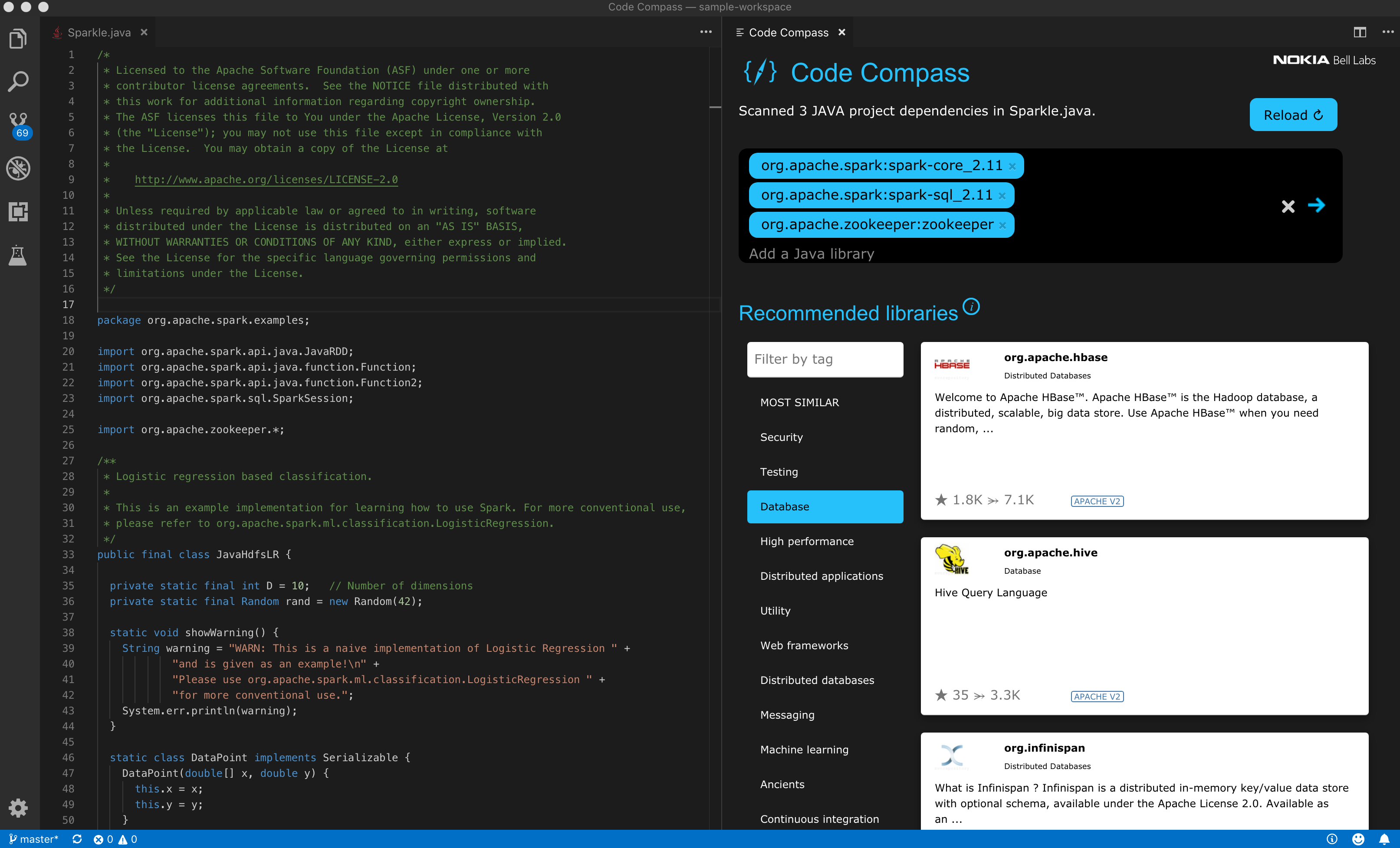
In this example the developer is editing a Java source file. When Code Compass is activated, it appears as a separate pane on the side. Code Compass automatically scans the import statements in the Java code and fills in the corresponding libraries as the search context. In this example the developer is looking for database-related libraries and developers familiar with Big Data processing in Java will not be surprised to see that the top results are “nosql” databases such as HBase and Hive rather than typical relational databases such as MySQL, given that the developer is already working with related libraries such as Spark.
The fact that Code Compass reads your code to seed the search should rightfully make you worry about the privacy of your code. Library dependencies are extracted locally in the browser or IDE before sending any search request to our server. The server never gets to see code, only library names imported in source files or declared as dependencies in manifest files.
Wrapping up
Just like word vectors and word2vec were a key enabler for many NLP tasks, we hope that library vectors and import2vec become a key enabler for many software engineering tasks. Code Compass is just one example of a practical tool making use of library vectors to help software developers be more productive.
Details about the import2vec method to train library vectors can be found in our MSR 2019 paper. Pretrained library vectors for Java, JavaScript and Python are available on Zenodo. Additional scripts used for data gathering and cleaning are available on GitHub.
Code Compass is available for trial. The source of our visual studio code extension and a description of our REST API are also on GitHub.
If you have feedback, please open an issue on GitHub or reach out on Twitter.
Now that you have a trusty compass to guide you, have fun exploring the open source jungle!